刚刚,DeepSeek V4 双版本正式上线!
(来源:机器之心Pro)

机器之心编辑部
终于,全球 AI 圈等待了几个月的 DeepSeek V4,它终于来了!
今天上午,DeepSeek API 文档上线,让我们看到了新版本的「庐山真面目」。
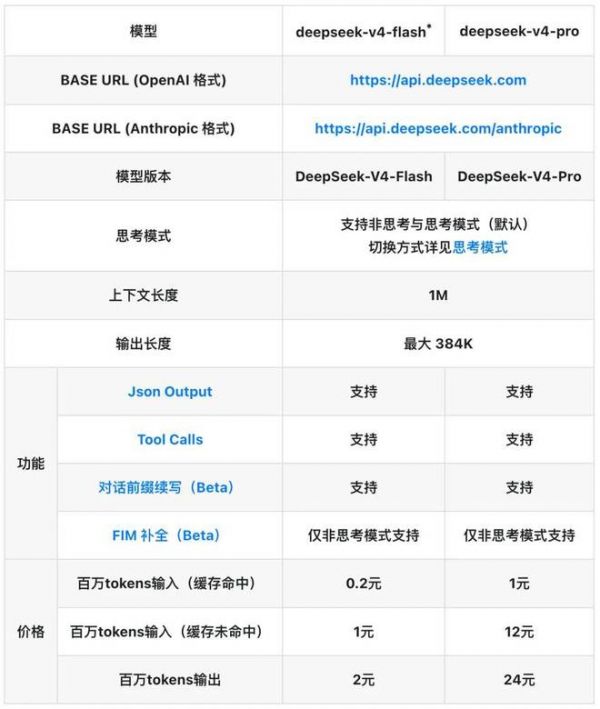
此次,DeepSeek V4 按大小会有两个版本,分别是DeepSeek-V4-Flash 和 DeepSeek-V4-Pro。上下文长度大家此前已经知道了,是 100 万 tokens。同时,输出长度最大为 384K tokens。
就在刚刚,DeepSeek 官方正式宣布上线并开源「DeepSeek-V4 预览版」
根据官方的介绍,此次 DeepSeek-V4 在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。

两个版本,V4-Pro 与 V4-Flash 的最大上下文长度均为 1M,且同时支持「非思考模式」与「思考模式」,其中思考模式支持 reasoning_effort 参数设置思考强度(high/max)。对于复杂的 Agent 场景建议使用思考模式,并设置强度为 「max」。
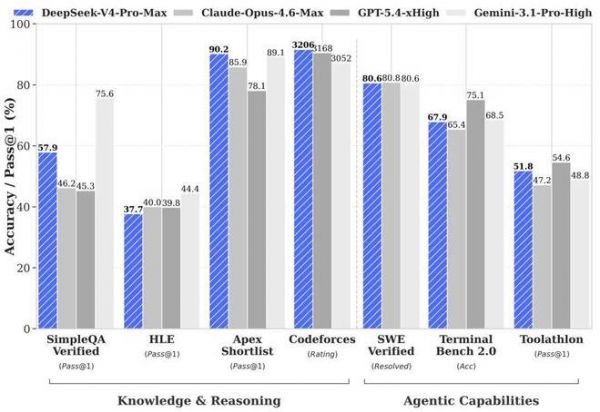
DeepSeek-V4 发布同时,也公布了其详细的技术报告。

该系列包括 DeepSeek-V4-Pro(1.6T 参数,49B 激活)和 DeepSeek-V4-Flash(284B 参数,13B 激活),两者均支持一百万令牌的上下文长度,旨在提升超长上下文场景下的性能。该系列的关键创新包括:
1.混合注意力架构:结合了 压缩稀疏注意力(CSA) 和 高度压缩注意力(HCA),这一新方法显著减少了计算复杂度,提升了长上下文处理的效率,特别适用于涉及数百万令牌的任务。
2.流形约束超连接(mHC):增强了传统残差连接,提高了信号在层之间传播的稳定性。
3.Muon 优化器:设计用于加速收敛和提高训练稳定性,Muon 优化器显著提升了训练过程中的模型性能。
4.训练和后训练管道:该模型在大量数据集(DeepSeek-V4-Flash 使用 32T 令牌,DeepSeek-V4-Pro 使用 33T 令牌)上进行了预训练,随后通过专门的训练和策略蒸馏进一步优化,确保它们在推理、编程和世界知识任务中表现出色。
5.长上下文效率:这些模型在推理 FLOPs 和 KV 缓存大小 上都实现了显著减少,使得处理一百万令牌成为可能。例如,DeepSeek-V4-Pro 在与前代模型 DeepSeek-V3 的对比中,FLOPs 降低了 73%,KV 缓存大小减少了 90%。
6.评估结果:DeepSeek-V4-Pro-Max 版本在推理和知识任务上设定了新基准,超越了之前的开源模型,并接近一些专有模型的水平。DeepSeek-V4-Flash-Max 在更多高效的参数规模下,提供了相当的推理性能。
总的来说,DeepSeek-V4 系列在大规模语言模型的效率上迈出了重要一步,能够有效处理超长序列,从而为复杂的长时间跨度任务开辟了新的可能性。
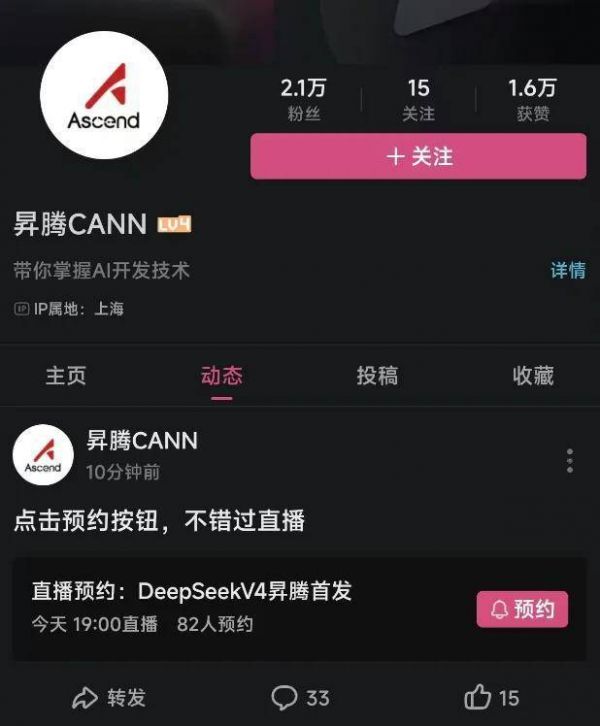
在另一边,大家一直在关心 DeepSeek V4 是否使用国产算力,结果也终于揭晓。之前就有报道 DeepSeek V4 新模型,将采用华为技术公司设计的最新芯片,也是真的。
我们发现,昇腾 CANN 将在今晚 7 点直播 DeepSeek V4在昇腾平台的首发
值得一提的是,寒武纪在软硬一体生态中,已经完成基于 vLLM 推理框架完成对 285B DeepSeek-V4-flash 和 1.6T DeepSeek-V4-pro 的Day 0 适配,适配代码已开源到 GitHub 社区。
DeepSeek 官方在发布推文最后说道:「不诱于誉,不恐于诽,率道而行,端然正己。」出自《荀子・非十二子》,是一种超然,任东西南北风的态度。
剩下的,就是大家亲自体验到 DeepSeek-V4 了!
相关推荐
刚刚,梁文锋被曝史上首次融资!DeepSeek V4彻底摆脱英伟达
连崩三天、核心离职、抛弃英伟达:DeepSeek V4 定档 4 月下旬!
据最新爆料:DeepSeek V4和姚顺雨的新混元模型,将同时于下月发布
DeepSeek V4 抛弃英伟达!GPT-6 也要来了?
DeepSeek V4来了!万亿参数+华为芯片,中国AI的"独立宣言"
DeepSeek崩溃10小时,这是好事啊,梁文锋得为V4冲击波做好准备
V4 发布前的 DeepSeek:特质、组织和梁文锋的独特目标
DeepSeek变冷淡了
DeepSeek“小版本更新”背后,V3和R1正融合成一个模型
DeepSeek vs 腾讯:一场对决,看清国产 AI 的两条突围路
网址: 刚刚,DeepSeek V4 双版本正式上线! https://m.xishuta.cn/newsview149045.html