DeepSeek多模态新范式:一张图压缩7056倍,思考能力反超GPT和Claude
(来源:图灵人工智能)

DeepSeek刚发完V4,就悄悄上线了多模态。目前正在灰度公测,如果你被灰度到,可以看到聊天窗多了个识图模式。
同时,DeepSeek多模态新范式技术也开源了。

当最强的AI看一张拥挤的聚会照片,你问它“有多少人戴眼镜?”,它可能给你一个流畅、自信却完全错误的数字。
不是因为它眼神不好,而是它在思考时没法像人一样,用手指着一个个数。
DeepSeek这项研究,恰好给AI装上了一根数字手指,它教AI在推理想法里直接画框框、标点点,结果出奇地好。
只用其他顶级模型一小部分的计算量,就在一堆考验空间感和逻辑的硬核测试里,和GPT-5.4、Claude-Sonnet-4.6这些顶尖模型打成了平手,甚至更好。
研究者们通过用视觉原语思考(Thinking with Visual Primitives)这一全新范式,将空间坐标变成AI思维链条的一部分,从而弥合了语言与视觉之间的指代鸿沟。
语言与视觉间的隐形鸿沟
今天的大模型已经足够聪明,它们看图识字,吟诗作对,甚至能解复杂的数学题。我们把这种需要深思熟虑的慢速思考模式叫做系统2思考。
但一个奇怪的瓶颈始终存在,当AI需要在复杂的空间布局里进行推理时,它的思维链条(Chain-of-Thought, CoT)就崩溃了。
过去,业界努力的方向是缩小感知鸿沟,也就是让AI看得更清楚。比如给图片切块,用高分辨率放大,确保模型能看见所有的细节。但看见不等于能推理。真正的麻烦,是指代鸿沟。
想象一下,你用纯语言向一个不在现场的人精准描述照片里某个人的位置。你会发现语言天然地模糊不清。
当AI试图在脑子里分析左边第二个穿红色条纹衫的男人时,它很容易在后续的逻辑推演中弄混,张冠李戴,最终在数数或空间判断上错误。这就是语言的模糊性导致的逻辑坍塌。
这就像一个人被要求在心里默默地数桌面上复杂的物品数量,却不允许他用手去指、去标记。念头转得飞快,但很快就缠在一起,忘了哪个数过,哪个没数过。
DeepSeek团队发现,这正是当前多模态大模型的常常出错的命门。
教会AI用手指着思考
怎么破局?DeepSeek团队给出的答案直接又优雅:把视觉标记,比如点和边界框,直接变成AI思考的基本单位。他们管这个叫用视觉原语思考(Thinking with Visual Primitives)。
这背后的想法非常人性化。当我们数一堆散乱的硬币,或是走一个复杂的迷宫时,我们本能地会伸出手指去指,以此降低大脑的认知负荷,保持逻辑的连贯性。
这项工作就是让AI模仿这种边指边想的能力。它在思考过程中,不再仅仅生成抽象的文字,而是直接输出一串串空间坐标,比如为一个目标画个框,或为一条路径打个点。
这些视觉基元就像锚一样,把飘忽的语言逻辑牢牢钉在图像的物理坐标上。
这项研究的另一个惊艳之处,是它的极致高效。
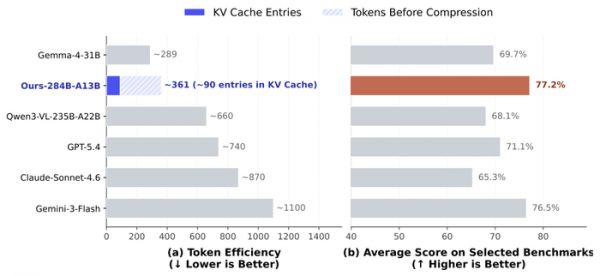
它构建在一个名为DeepSeek-V4-Flash的紧凑模型架构上。这个架构用了压缩稀疏注意力机制,能把海量的视觉信息狠狠压缩,一张大图的全部信息在AI的记忆里最终只占大约90个存储单元。
相比之下,其他顶级模型可能需要上千个单元来处理同样的图。从原始像素到最后存储,信息的压缩率能达到惊人的7056倍。这意味着,它能用少得多的算力,达到甚至超越巨无霸模型的认知深度。
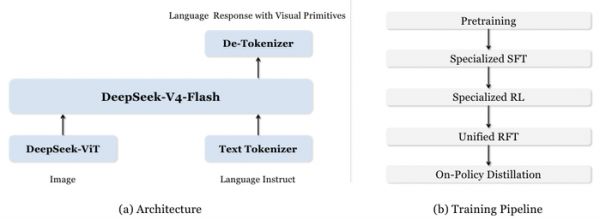
整个训练过程就像培养一位专家,分成了三个阶段。
第一阶段:打地基,学画框。
研究人员首先得教会模型最基础的技能:准确地输出一个框或一个点。虽然网上有一些现成的标注数据,但数量少、多样性也差。为了培养一个通才,他们发动了一场大规模的网络数据挖掘,一口气狂揽了近9.8万个可能包含目标检测标注的数据源。
数据是挖来了,但质量良莠不齐,有的标签是没意义的机器代码如0、1,有的是像我室友这样无法泛化的私人标签,还有的是工业场景里OK这类含糊不清的评价。对此,他们设计了一套由AI驱动的自动质检流水线。第一步是语义审查,像是给数据做智力体检,把那些语无伦次、无法理解的类别标签直接扔掉。这一轮筛下来,只留下了4.3万个数据源。
接着是更严格的几何质量审查。机器会检查框是不是把物体拦腰截断,是不是有很多该标的都没标,或者画了个几乎覆盖全图的巨框,这通常意味着数据是图像分类任务伪装的,毫无定位价值。经过这番去伪存真,最终保留下3.1万多个高质量数据源。为了平衡数据,他们按类别进行采样,最终整理出一个超过4千万样本的高质量数据集。
同时,为了教模型画点,他们用了一个巧妙的设计,一个能画框的模型天然就能画点,因为一个框无非就是由左上和右下两个点定义的。这样一来,一个拥有强大框标注能力的模型,可以无缝迁移到点标注的任务上。
第二阶段:练专家,专攻系统2难题。
有了基础画框能力的基座模型,下一步是在后训练阶段,让它成为解决特定难题的专家。研究者专门设计了四个能逼出视觉推理能力的魔鬼训练营。
第一个训练营是数数。AI的计数能力一直很糟糕。对于任务分解,他们把计数分成了粗粒度和细粒度两种。粗粒度数一般类别,比如数数有多少条狗,AI被训练成先一次性把所有狗用框定位出来,再统计数量。细粒度计数则更有挑战性,比如数数趴在地上白色的狗。
他们利用GQA数据集的场景图谱,精心合成了带复杂约束的计数问题,并引导模型生成一个逐步扫描、逐个验证的思考链。

上图展示了这两种计数的训练示例,模型先把目标具体化,然后用框把所有相关实体都锚定好,再基于这些视觉锚点进行系统性的计数。
第二个训练营是空间推理。他们除了利用自然场景数据,还引入了CLEVR这个经典的合成数据集。在这个工具里,他们能生成有控制、有明确场景图谱的多步推理问题。对于每一个问题,都有精确的程序执行轨迹,能把每一步推理映射到具体的物体上。
他们把这种轨迹转译成带框的思考链,让模型学会一手握数据,一手画框做逻辑推理。为了增强模型的可靠性,他们还特意做了负样本训练,即当问题中提到的物体或关系不存在时,模型必须学会基于视觉证据诚实地拒绝回答,而不是瞎编。

上图就是一个空间推理的示例,模型先是分析意图,定位到关键的灰色金属球,再逐一排查其他物体,用框来辅助完成多跳的逻辑推断。
第三个和第四个训练营则是更烧脑的迷宫导航和路径追踪。这两个任务的设计初衷,是逼出模型规划路线、处理拓扑连接的能力。他们用深度优先搜索、Prim等算法生成了海量形态各异、难度递增的迷宫和曲线图,网格形状包括矩形、圆形、六边形等。
一个关键的设计是难度控制,迷宫的难度不靠缩小图片让人看不清,而是靠加大网格数量,迫使模型在推理中串联起成百上千步的局部判断。路径追踪任务则要求模型顺着一条指定的线,穿过各种交叉缠绕的线条,最终找到正确的终点。研究者称之为交点消歧义,即模型必须在每一个岔路口调用局部几何连续性原语,判断哪条分支才是对的。

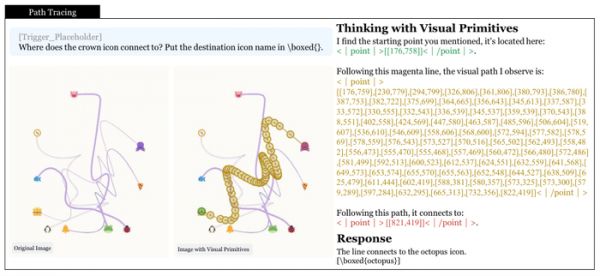
上面两图分别展示了迷宫导航和路径追踪的训练数据。在迷宫里,模型要像用深度优先搜索算法一样步步为营,探索死路则回溯;在路径追踪里,模型则要生成一串坐标点序列,沿着目标曲线不断前进,尤其在曲线密集交叉的区域,点会特别密,像人一样在复杂处放慢速度仔细看。
为了让专家更专,他们采用了一个先分后合的策略。基于基础模型,一份数据专门训练用框思考的专家,另一份数据专门训练用点思考的专家。训练中不仅监督回答是否正确,还用了强化学习,通过精心设计的奖励模型来调教模型。
比如对于数数,奖励不是简单地对错,而是基于预测值和真实值的相对误差的指数衰减,这给了模型更平滑、更细腻的学习信号。
对于迷宫,奖励模型更复杂,它会一步步检查模型有没有穿墙而过的违规操作,一旦发现就认为后续的探索都因果无效了,并以此计算探索进度、完整性和最终路径的有效性,给每一个正确应用的视觉原语行为都打上分。
算得少,跑得赢
最终模型的实力,在严格测试中得到了验证。整场测试严丝合缝地用了统一标准:所有模型都通过API在同样的提示词下进行评估。对于支持配置推理预算的模型,全都拉平设为低挡位,以求公平。
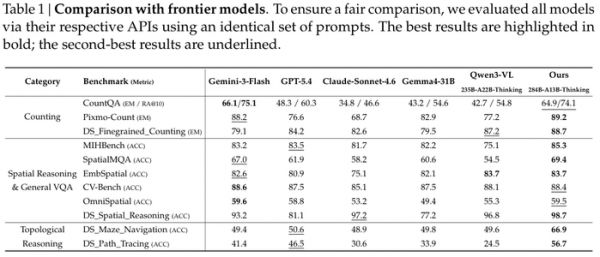
模型在计数、空间推理等核心任务上,与GPT-5.4、Claude-Sonnet-4.6等巨头的顶尖模型打得有来有回,甚至在一些项目上明显领先。
你会发现一个有意思的现象。在CountQA和SpatialMQA这种更偏传统问答的测试上,各家分数有高有低,拉不开差距。
可一旦进入特别设计的DS系列硬核测试,情况就完全不同了。在DS_细粒度计数(DS_Finegrained_Counting)上,模型拿到88.7分,略高于GPT-5.4的84.2。
更夸张的是在迷宫和路径追踪这两项上,模型分别达到了66.9和56.7分,把只拿到50分上下甚至30多分的对手远远甩在了身后。
这两项测试,考的纯粹是逻辑连贯性和空间拓扑感,这就很好地说明了,直接把空间坐标作为思考的一部分,相比纯粹用语言思考再转换成坐标的路径,在复杂的链式推理上有着结构性优势。
别忘了,这些成绩是建立在极高的视觉处理效率之上的。模型在KV缓存中只保留了大约90个条目来处理一张800x800分辨率的图片,就交出了极具竞争力的答卷。
研究者也坦诚了目前的局限。分辨率瓶颈依然存在,在需要极致精细分辨的场景下,边界框可能还不够精确。
当前模型的能力也还需要特定的词语来触发才能激活,不够自主。
利用点作为视觉原语来解决复杂的拓扑问题,其泛化能力也还有待加强。
但这项研究的核心思路依然振聋发聩。
多模态智能的未来,关键或许在于打造一套更精确、更少歧义、能将语言和视觉世界牢牢连接起来的指代机制。
参考资料:
https://github.com/deepseek-ai/Thinking-with-Visual-Primitive
相关推荐
DeepSeek发布多模态论文又连夜删除
凌晨突袭!新版DeepSeek代码能力封神,Claude 3.7王座不保?
编程表现超越Claude和GPT?DeepSeek准备第二次震惊全世界
DeepSeek小心,帝国反击战打响了
DeepSeek开源新模型
Ilya刚预言完,世界首个原生多模态架构就来了:视觉和语言被焊死
为什么没人说DeepSeek的数学和代码?
万字长文,聊聊下一代AI Agent的新范式
2026 AI 商业中场:从原生多模态到超级入口
OpenAI推出GPT-4o,多模态AI概念股暴涨
网址: DeepSeek多模态新范式:一张图压缩7056倍,思考能力反超GPT和Claude http://m.xishuta.cn/newsview149281.html